Case Study
Homelab Infrastructure
The live demo runs on a self-hosted Proxmox homelab, exposed through Cloudflare Tunnel — with a private registry, declarative edge config, and a single-command local environment that mirrors production.
The Problem
Most portfolio projects deploy to one cloud and call it done. That tells a recruiter the candidate can click "deploy" in a managed UI. It doesn't show that they understand what happens underneath.
I wanted the live demo to run on infrastructure I actually owned — Proxmox servers in my home office — while still demonstrating production patterns: zero-trust edge networking, a private container registry, infrastructure-as-code, and a local dev environment that a new contributor can boot with one command. No "works on my machine" surprises between local and prod.
The Solution
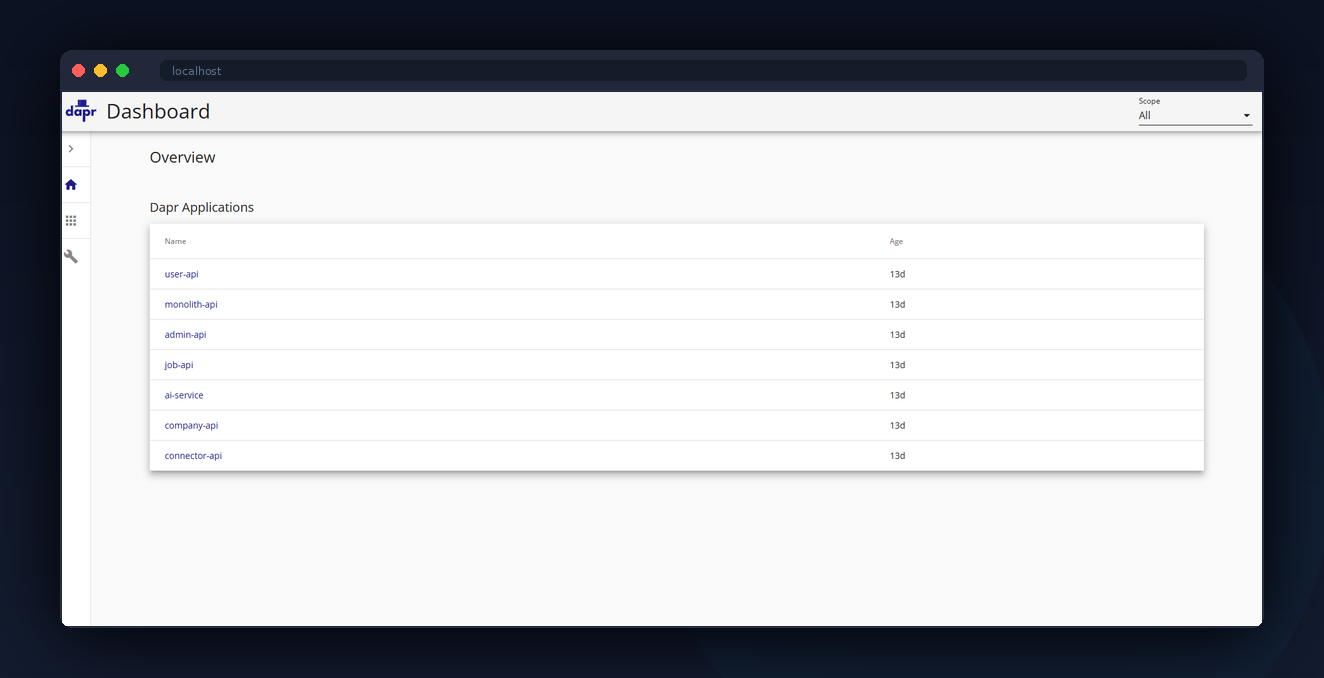
Seven purpose-built hosts, each with a single responsibility: two application hosts (dev + prod), an infrastructure host running Docker alongside the Proxmox hypervisor (reverse proxy, Cloudflare tunnel daemon, WireGuard, Portainer, Uptime Kuma), a dedicated build VM (two isolated GitHub Actions runners, private Docker registry, Docker Hub pull-through cache), a secrets host (HashiCorp Vault plus Grafana), an observability VM (OpenTelemetry Collector, Jaeger, Prometheus, Grafana Alloy), and a DNS host (Pi-hole).
Public traffic enters through a Cloudflare Tunnel — no open inbound ports on the home network, no dynamic DNS, no VPN for end users. WAF rules, DNS records, and ingress routes are all declarative: a single GitHub Actions workflow reads deploy/cloudflare/tunnel-config.json and syncs Cloudflare to match.
Locally, .NET Aspire orchestrates the entire platform — 36 resources including .NET services, Dapr sidecars, SQL Server, PostgreSQL, Redis, RabbitMQ, Keycloak, Elasticsearch, Jaeger, Grafana, and both Angular apps — with one command and dependency-aware startup ordering.
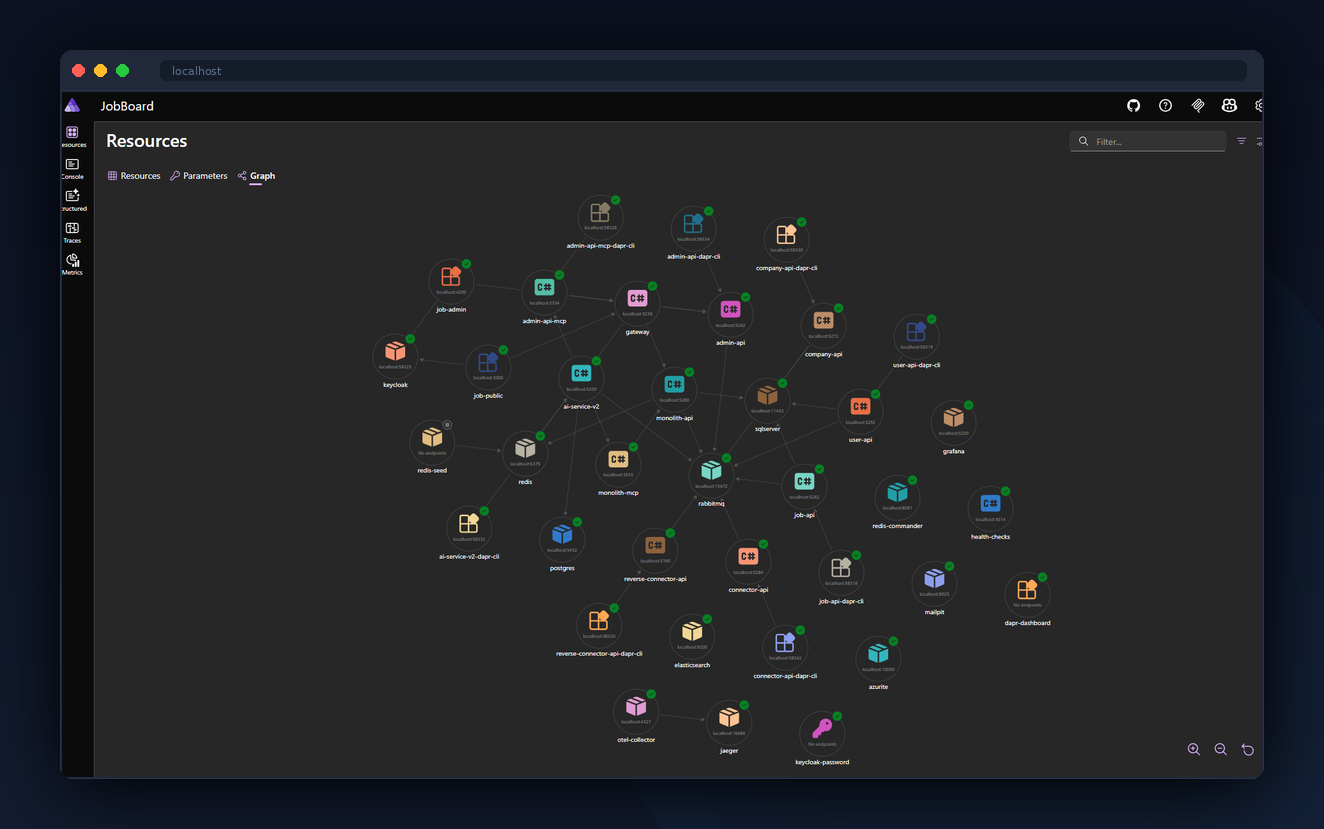
Architecture
The homelab runs on a Proxmox cluster with purpose-built hosts. Each has a static LAN IP and one job:
- 192.168.1.200 — dev host. Runs the dev Docker Compose stack (gateway, monolith, microservices, AI service, two Angular apps, Dapr sidecars).
- 192.168.1.112 — prod host. Same stack, prod configuration.
- 192.168.1.151 — build infrastructure. Two GitHub Actions runners (labeled
proxmox-devandproxmox-prod), the private Docker registry atjobboard-registry.elkhair.tech, and a Docker Hub pull-through cache. Dedicated so builds never compete with running services on dev/prod. - 192.168.1.150 — general infrastructure. Nginx Proxy Manager (LAN TLS termination), Cloudflare tunnel daemon, WireGuard, Portainer, Uptime Kuma. This is the Proxmox host itself running Docker alongside the hypervisor.
- 192.168.1.115 — HashiCorp Vault (
:8200) + Grafana (:3000, exposed publicly atgrafana.elkhair.tech). Vault is the single source of truth for secrets (DB credentials, Keycloak client secrets, API keys, OAuth2 client credentials), and is configured with transit-seal auto-unseal so reboots don't require manual intervention. Every Dapr sidecar mounts asecretstores.hashicorp.vaultcomponent pointed here. - 192.168.1.160 — observability. OpenTelemetry Collector (
:4318HTTP /:4317gRPC, exposed publicly atotel.elkhair.tech), Jaeger (:16686, exposed atjaeger.elkhair.tech), Prometheus, and Grafana Alloy (Faro browser-telemetry receiver). - 192.168.1.123 — Pi-hole. Local DNS overrides for internal-only subdomains.
Two public domains point at the same infrastructure: eelkhair.net (the original) and elkhair.tech (the portfolio-branded one). Both resolve through the same Cloudflare Tunnel, both carry valid certificates at the edge, and CORS is allowlisted across zones so Angular apps on one domain can call APIs on the other. This lets me evolve branding without rebuilding infrastructure.
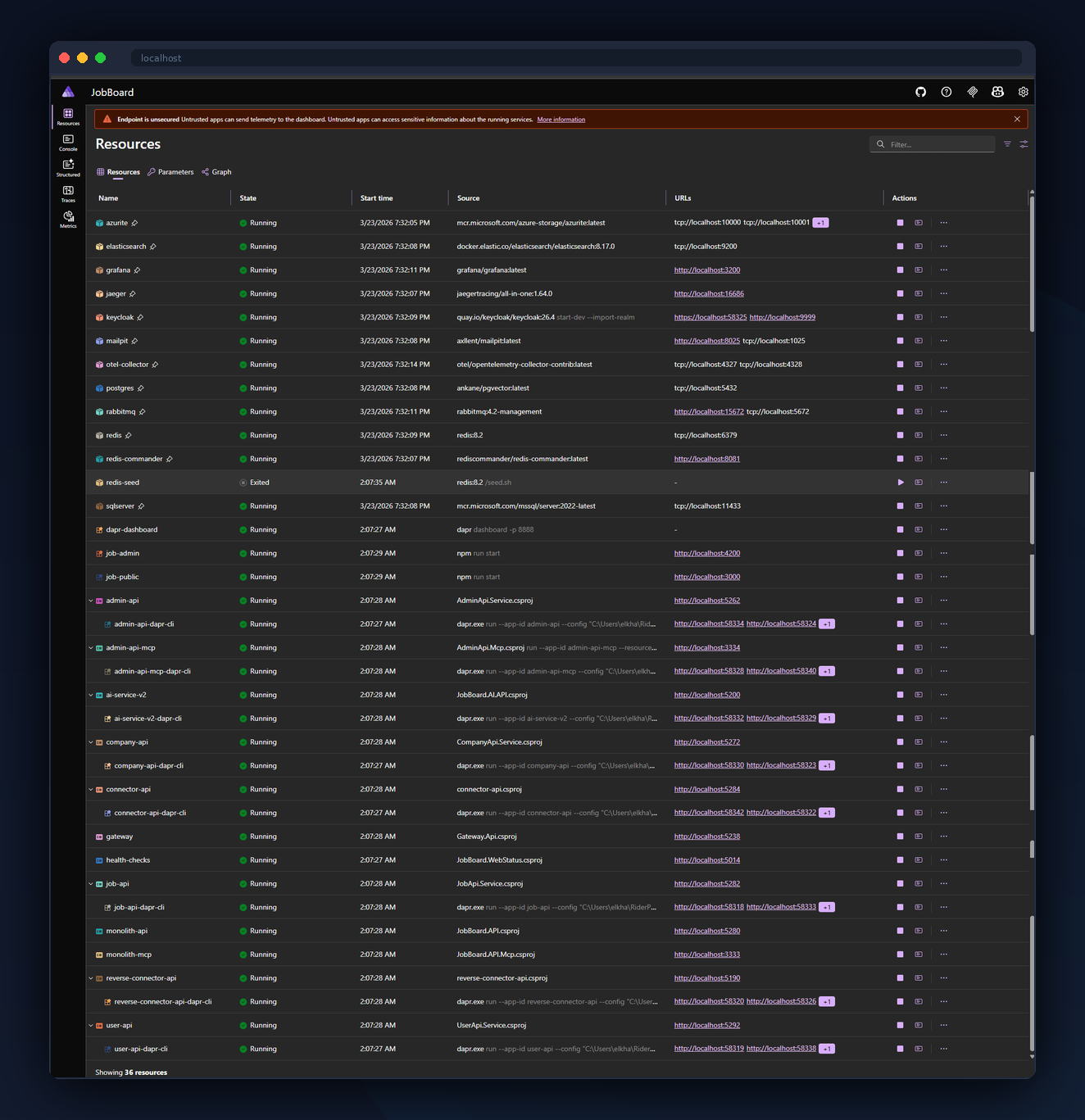
What You See
As a visitor, you don't see any of this. You type jobs.elkhair.tech, TLS terminates at Cloudflare's edge, traffic flows through the tunnel to the reverse proxy on 192.168.1.150, which routes to the gateway container, which routes to either the monolith or microservices based on the x-mode header. The experience feels identical to a cloud deployment.
As a developer cloning the repo, you run one command: dotnet run --project aspire/JobBoard.AppHost. Aspire pulls down container images, seeds databases from backups (.bak and .dump files via a single "seed-runner" container that runs SQL Server, Postgres, and Redis seeds in parallel), waits for health endpoints, then launches .NET projects as native processes (debugger-attachable) with Dapr sidecars wired up. 36 resources, dependency-ordered, in a single dashboard.
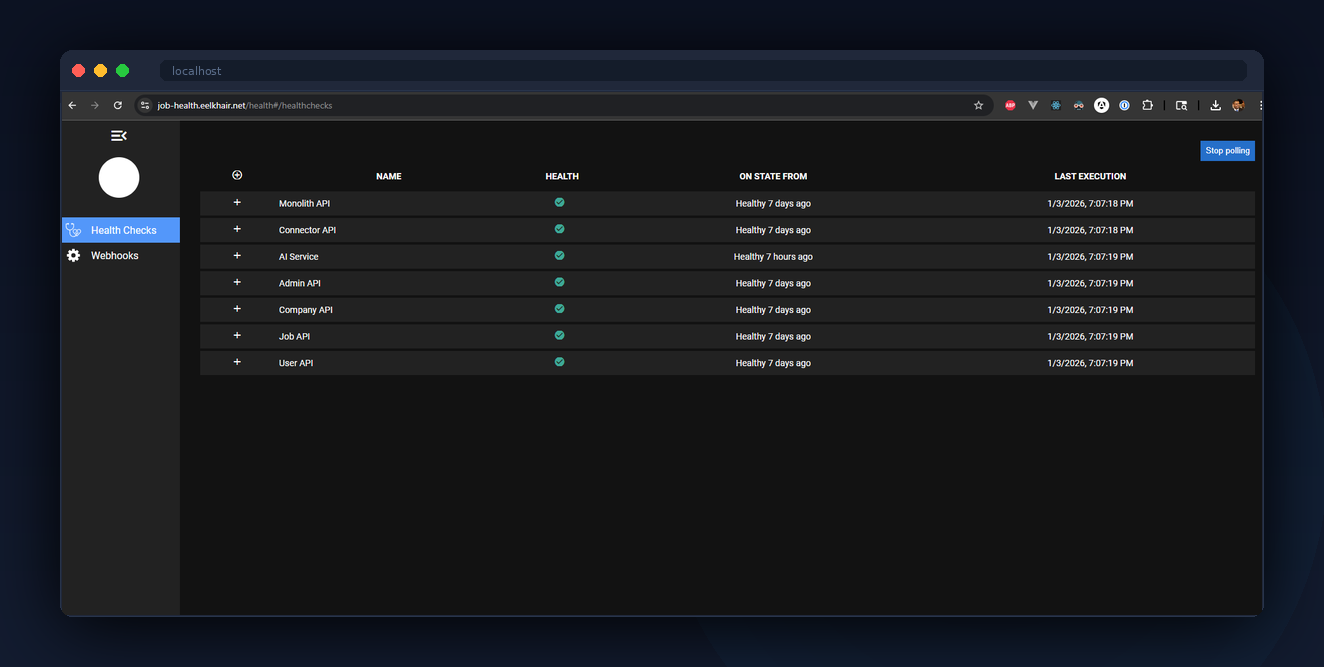
As a recruiter, you don't have to take my word for any of this. Jaeger is public at jaeger.elkhair.tech — open it after you click around the live apps and you'll see your own requests as distributed traces, spanning gateway → monolith or microservices → Dapr pub/sub → AI service. Grafana is public at grafana.elkhair.tech (anonymous viewer role) with dashboards for Web RUM, Monolith Overview, AI Service, and "Find by Trace ID" for end-to-end log/trace correlation.
Behind the Scenes
Declarative Cloudflare. The tunnel's ingress rules, public hostnames, DNS records across both zones, WAF rules, and zone-level security settings are all committed at deploy/cloudflare/tunnel-config.json. A GitHub Actions workflow (cloudflare-tunnel.yml) reads that file and uses the Cloudflare API to reconcile edge state on every merge. Adding a new subdomain is a pull request, not a dashboard click.
Isolated build infrastructure. Two GitHub Actions runners live on a dedicated VM (192.168.1.151) — one labeled proxmox-dev, one labeled proxmox-prod. Builds no longer compete for CPU, RAM, or disk I/O with running services on the application hosts. From the runner VM, deploys reach the target hosts over Docker contexts via SSH (docker --context job-board-dev compose up -d), with SSH ControlMaster multiplexing so compose's parallel API calls share a single TCP connection instead of hammering sshd.
Environment-isolated image tags. Backend services push as :dev and :prod instead of a shared :latest. Before this, both environments raced to overwrite each other's :latest and a single corrupted manifest took both down. Now dev and prod have independent image lineages in the same registry.
Docker Hub pull-through cache. A second registry:2 container on the build VM (port 5001) is configured as a proxy to registry-1.docker.io. Dev and prod /etc/docker/daemon.json points registry-mirrors at it. Docker Hub rate limits or transient network blips no longer cascade into failed deploys — common images like daprio/daprd and mcr.microsoft.com/dotnet/* are served from LAN.
Private registry with garbage collection. The self-hosted registry at jobboard-registry.elkhair.tech runs with REGISTRY_STORAGE_DELETE_ENABLED=true, and a weekly cron runs registry garbage-collect --delete-untagged to reclaim untagged blob space. Without this, every CI build leaks blob storage forever — a common self-hosted-registry foot-gun.
Seed runner pattern. Aspire's WaitFor() only works if the thing being waited on exposes a health endpoint. The seed runner is a single persistent container that runs Redis, SQL Server, and Postgres seeding scripts in parallel on startup, then opens an HTTP health endpoint on port 8080 and idles. Every service uses .WaitFor(seedRunner), which blocks until all three databases are seeded. This eliminated a cold-start race condition where services started before their databases were ready.
Local DNS caveat. Pi-hole overrides *.eelkhair.net to 192.168.1.150 so internal LAN traffic skips the public internet path. A wildcard Let's Encrypt cert on the Nginx Proxy Manager makes that work. The same trick does not work for *.elkhair.tech — no wildcard cert — so elkhair.tech always resolves publicly through Cloudflare, even from inside the house. A one-line rule difference; discovered the hard way.
Secrets via HashiCorp Vault. Every service reads its secrets (connection strings, Keycloak client secrets, API keys, OAuth2 client credentials for service-to-service calls) from a self-hosted Vault instance at 192.168.1.115:8200, accessed through Dapr's secretstores.hashicorp.vault component. Each service has a scoped secret.yaml in its Dapr components directory; rotation is a Vault write plus a sidecar restart, never a code change or a redeploy. No secrets live in compose files, no secrets live in Git. The same config surface exists in Azure under secretstores.azure.keyvault — the service code doesn't know the difference.
Geo enrichment without rate limits. Every frontend (landing SSR, Angular admin, Angular public) attaches visitor country/city/region/lat/lon to telemetry spans for the "Visitors by city" map. Originally each call hit ipapi.co's free tier, which throttled at ~1000 requests/day per source IP — a container restart would wipe the in-memory cache and burn the day's budget in minutes. Now the gateway hosts /api/public/geo backed by a MaxMind GeoLite2 City database baked into the gateway image at build time. Lookups are sub-microsecond, cost nothing, never rate-limit, and a weekly GitHub Actions cron pulls the latest mmdb. All three frontends point at the gateway for geo — one mmdb, one source of truth, no external dependency.
Vault auto-unseal. A second small Vault instance on 192.168.1.150 acts as a transit-seal backend; the main Vault on 192.168.1.115 wraps its master key with the transit Vault's key. After a reboot, the main Vault calls the transit Vault to unwrap and unseal itself — no manual intervention, no vault operator unseal ceremony. Costs one extra container; eliminates the "Vault is sealed and nothing can read its secrets" cascade that takes down every service depending on it.
Cold-standby landing page. The landing site is also deployed to Cloudflare Pages at landing-backup.elkhair.tech on every merge. When the homelab goes dark — ISP outage, power cut, hardware failure — a single command (deploy/cloudflare/failover-landing.sh cf [dev|prod|both]) upserts the apex and www CNAMEs to point at the Pages deployment instead of the tunnel. Running it with proxmox as the first argument flips back. The script is idempotent and scoped (dev, prod, or both), so re-runs are safe and partial failover is one flag away. DNS inside Cloudflare propagates near-instantly; the 300-second TTL caps external cache. It's manual by design — an outage here is never a surprise and doesn't warrant the cost of Cloudflare Load Balancing.
Key Decisions
Proxmox homelab over single cloud provider
Why: Full control over the stack, zero ongoing cloud spend, and a realistic story about understanding infrastructure end-to-end — not just the managed control plane. Bicep IaC is still committed for Azure as a reference deployment path.
Alternative: Azure Container Apps only. Simpler to operate but tells a less differentiated story for a portfolio, and the monthly bill would be meaningful for a project with no revenue.
Cloudflare Tunnel over self-managed VPN + DDNS
Why: Zero open inbound ports on the home network. No dynamic DNS, no port-forwarding, no NAT traversal. TLS terminates at Cloudflare's edge with Universal SSL. WAF and DDoS mitigation are free.
Alternative: WireGuard + DuckDNS. Works but exposes the home network surface and requires managing certificates and renewals manually.
.NET Aspire over Docker Compose for local dev
Why: Aspire orchestrates .NET projects as native processes (debugger-attachable) while still managing container infrastructure and Dapr sidecars. Compose forces you to containerize everything — slow rebuild cycles, no debugger attach. Compose is still used for dev and prod deployments, so the production story stays unchanged.
Alternative: Docker Compose for everything or Microsoft's retired tye tool. Aspire won on debugger ergonomics and active maintenance.
Declarative Cloudflare config over clicking the dashboard
Why: Ingress rules, WAF rules, and DNS records are version-controlled, reviewable in PRs, and reproducible. Losing the Cloudflare dashboard is a zero-impact event — re-running the workflow restores everything.
Alternative: Manual dashboard configuration. Faster initially but drift is invisible and disaster recovery is guesswork.
Dedicated build VM over runners on the app hosts
Why: Originally the GitHub Actions runners lived on the dev and prod application VMs. Every docker build for the .NET monorepo competed with running services for CPU, RAM, and disk I/O — request latency would spike during a deploy. Moving runners to a single dedicated VM (along with the registry and Docker Hub pull-through cache) isolates build load from runtime load entirely. Deploys reach the app hosts via Docker contexts over SSH, with ControlMaster multiplexing.
Alternative: Keep runners on the app hosts and accept the build/runtime contention. Or use GitHub-hosted runners — but that loses the local layer cache, the local registry pull-through, and the BuildKit cache reuse that make subsequent builds quick.
Centralized geo enrichment on the gateway
Why: Every frontend needs visitor country/city/region for span tagging. Doing it per-app meant landing called ipapi.co (rate-limited), and Angular apps called landing's /api/geo (same dependency, doubled). Putting MaxMind on the gateway gives one mmdb, one HTTP endpoint, zero external dependencies. Landing SSR also calls the gateway over the LAN bridge network — adds 1-2 ms but eliminates the rate-limit failure mode.
Alternative: mmdb in every container. Wastes ~65 MB per image, and Next.js's edge runtime transformer strips runtime imports needed to load it from inside the landing app anyway.
Tradeoffs & Lessons Learned
- Home power and ISP are the SLA — with a manual escape hatch. A power outage or ISP blip would take the dynamic parts of the demo down (live apps, APIs), but the landing page itself survives: Cloudflare Pages hosts a cold standby at
landing-backup.elkhair.tech, and the failover script flips the apex CNAME to it in one command. Good enough for a portfolio; not a substitute for real HA. - Single-host ceiling per environment. Docker Compose has no rolling updates, no horizontal auto-scaling, no self-healing orchestration. The architecture is designed to support all of it (stateless services, external state stores, health-gated readiness), but proving it would require migrating to Kubernetes or Container Apps.
- Registry disk fills silently. Before the weekly GC cron landed, image pushes started returning HTTP 500 mid-blob-upload as
/mnt/storagefilled. The storage path looks like a network mount but is actually a local disk. Monitoring disk on the infrastructure VM is now the first thing I check when pushes fail. - Three configuration sources. Between Dapr vault, Redis config store, and environment variables, adding a new service means touching three places. Aspire local papers over this; production deployments don't. Worth it for the flexibility, but the surface area is real.
- Build infrastructure is a single point of failure for new deploys — but not for runtime. If the build VM goes down, no new images push and no deploys go out, but every running container on dev and prod keeps serving traffic untouched. Acceptable: a deploy outage is a slow-burn problem (caught at the next merge), while a runtime outage is a fast-burn problem (immediate user impact). Worth designing the failure domains so the urgent thing is the resilient one.
- Cloudflare is a single vendor dependency — but the blast radius is bounded. Both the tunnel and the backup Pages deployment live in the same Cloudflare account, so a full-account issue would still take everything down. The failover is a homelab fallback, not a Cloudflare fallback. Acceptable for a portfolio; a real product would want a second edge provider.